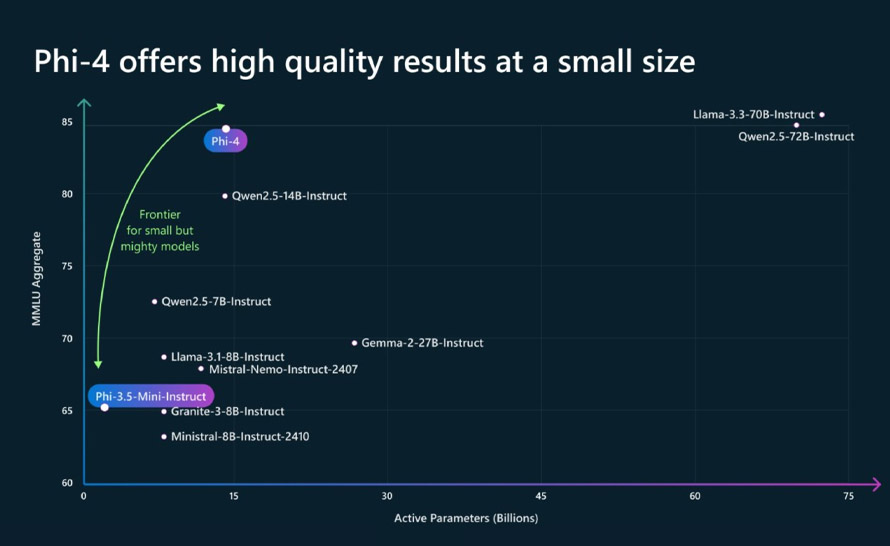
Oprócz dużych modeli językowych (LLMs), wzbudzających najwięcej zachwytów, twórcy sztucznej inteligencji tworzą też małe modele językowe (SLMs), które mogą działać lokalnie nawet na zwyczajnych urządzeniach, takich jak smartfon. Jednym z nich jest Phi rozwijany przez Microsoft. Jego najnowsza wersja Phi-4 została wydana w zeszłym tygodniu. Mimo niewielkiego rozmiaru pokonuje ona w niektórych benchmarkach nawet popularne, duże modele.
Phi-4 to mały model językowy (Small Language Model) z 14 miliardami parametrów. Jak podaje Microsoft, cechuje się on wysoką wydajnością w rozumowaniu/wnioskowaniu przy problemach matematycznych dzięki wysokiej jakości, syntetycznym zestawom danych, organicznym danym i ulepszeniom potreningowym. Dane syntetyczne do trenowania tego modelu zostały wygenerowane za pomocą kilku technik, takich jak multi-agent prompting, self-revision workflows i instruction reversal. Wygenerowane syntetyczne dane stanowią większość danych treningowych dla Phi-4. Microsoft wykorzystał również techniki, takie jak rejection sampling, aby udoskonalić wyniki modelu w procesie po treningu.
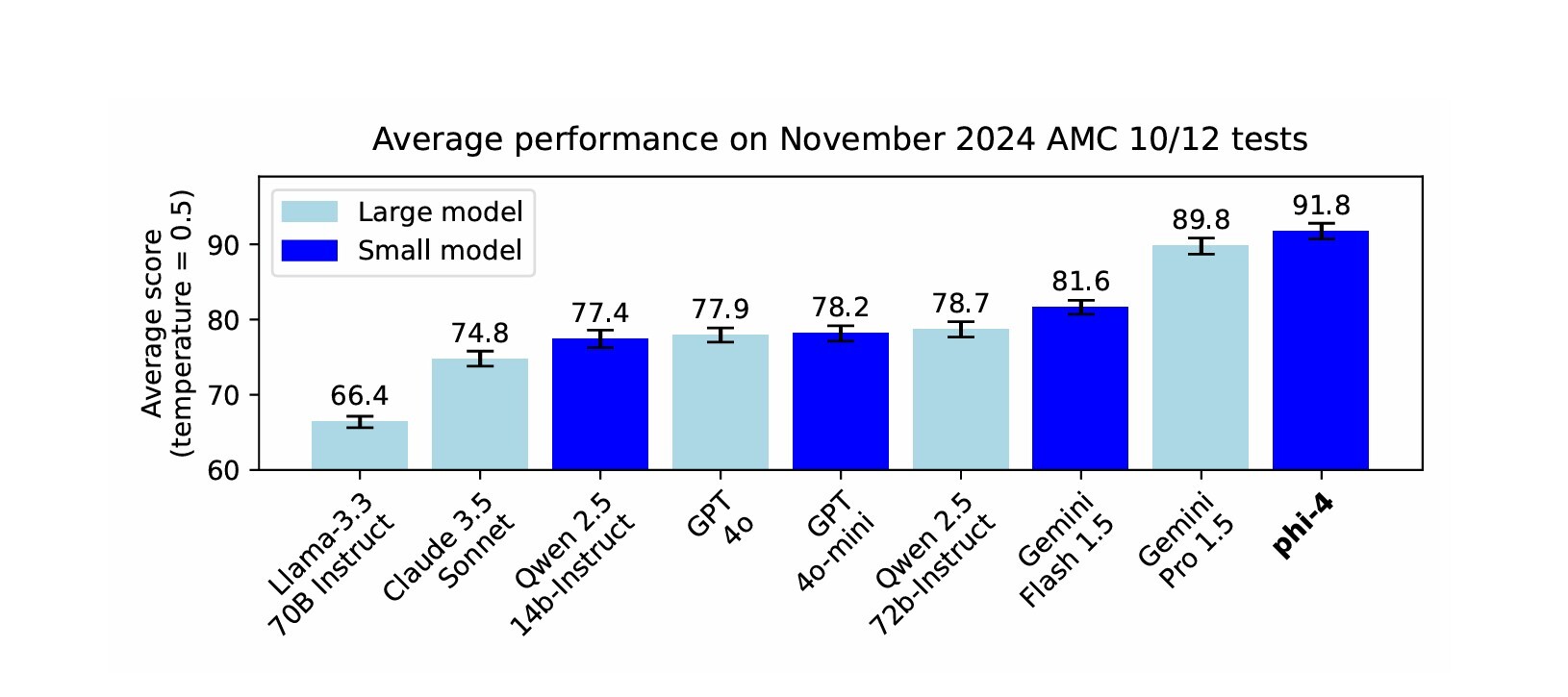
Co jednak szczególnie interesujące, to wyniki Phi-4 w benchmarkach. W niektórych wyprzedza nawet duże modele językowe, takie jak GPT-4o czy Gemini 1.5 Pro. A jakie są jego słabości? Te wynikają głównie z jego podstawowej cechy, czyli małego rozmiaru. Model będzie halucynował wokół wiedzy faktycznej i nie będzie rygorystycznie przestrzegał szczegółowych instrukcji. Aby jednak zapewnić mu bezpieczne działanie, twórcy współpracowali z niezależnym zespołem AI Red Team (AIRT) w Microsoft, co pozwoliło zidentyfikować ryzyka bezpieczeństwa zarówno w przeciętnych, jak i wrogich scenariuszach użycia.
Phi-4 jest już dostępny w Azure AI Foundry na licencji Microsoft Research License Agreement (MSRLA). Microsoft ma też go wypuścić w Hugging Face. Dowiedz się więcej z naszych artykułów:
a8fe91a.jpg)