Microsoft ogłosił nowe narzędzie do wykrywania i poprawiania halucynacji w odpowiedziach generatywnej AI (GenAI). Halucynacje AI oznaczają wymyślanie lub udzielanie przez sztuczną inteligencję błędnych odpowiedzi, gdy nie może ona dotrzeć do trafnych informacji w swojej bazie wiedzy lub w Internecie. Nowa funkcjonalność w ramach Azure AI Content Safety pomoże zidentyfikować taką potencjalnie szkodliwą i wprowadzającą w błąd zawartość.
Azure AI Content Safety to usługa wykrywająca krzywdzące treści zarówno wprowadzane przez użytkownika, jak i generowane przez AI. Jest ona wykorzystywana z Microsoft Copilot i oferowana deweloperom poprzez interfejsy API zarówno tekstowe, jak i obrazowe. Jeszcze inna funkcjonalność (Groundedness Detection) potrafi wykrywać, czy odpowiedzi dużych modeli językowych opierają się na wybranych przez użytkownika źródłach. Jako że obecne LLMs produkują czasem nieprawdziwe lub nieoparte na faktach odpowiedzi, deweloperzy mogą je zidentyfikować dzięki temu właśnie API. Najnowsza możliwość dotyczy jeszcze innego rodzaju nieprawidłowości – bezpośrednio halucynacji.
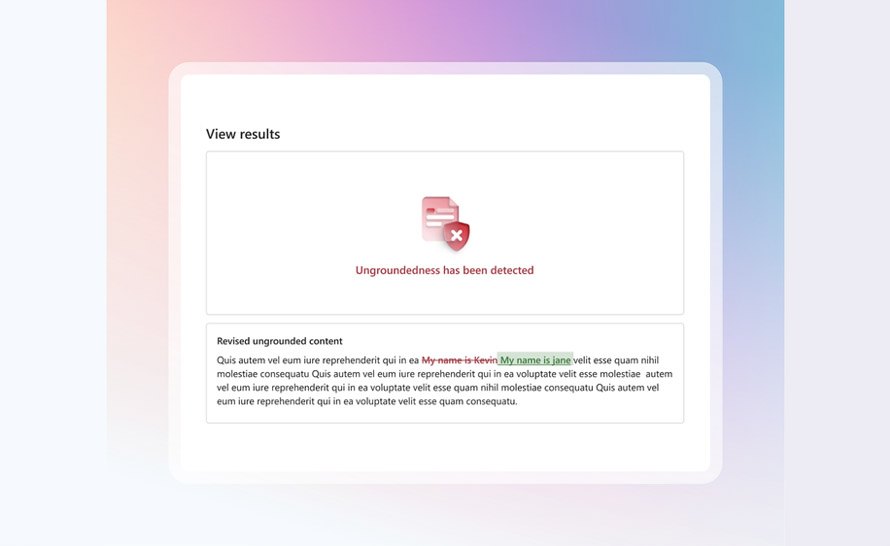
Funkcja korekty (Correction Capability) w Azure AI Content Safety będzie wspomagać klientów zarówno w zrozumieniu, jak i podejmowaniu działania w odniesieniu do bezzasadnych, nieuziemionych, nieugruntowanych w faktach (ungrounded) treści i halucynacji. Usługa jest w stanie zarówno identyfikować, jak i poprawiać halucynacje w czasie rzeczywistym, zanim jeszcze odpowiedzi dotrą do użytkowników aplikacji AI. Jak to działa?
- Deweloper aplikacji musi włączyć możliwość korekty.
- Gdy zostanie wykryte nieugruntowane zdanie, wywoła to nowy request do modelu generatywnej AI z prośbą o korektę.
- LLM oceni to bezzasadne zdanie w zestawieniu z "uziemiającym" dokumentem.
- Jeżeli zdanie nie zawiera żadnej treści odnoszącej się do tego dokumentu, może zostać całkowicie odfiltrowane.
- Jeśli jednak zawiera treść pochodzącą z tego dokumentu, model bazowy przepisze nieugruntowane zdanie, aby pomóc w uzyskaniu zgodności z dokumentem.
Halucynacje AI to fenomen dotykający duże modele językowe (LLMs, takie jak GPT), który może być szczególnie groźny, gdy np. użytkownicy szukają informacji medycznych. Znany jest też przypadek zatrucia rodziny, która zakupiła atlas grzybów wygenerowany przez AI w formie e-booka.
a8fe91a.jpg)