
W ostatnich latach Microsoft Research odniósł wiele sukcesów na polu przetwarzania języka naturalnego przez sztuczną inteligencję, wliczając w to m.in. tłumaczenia maszynowe i rozumienie mowy. Teraz badawczy dział firmy informuje o kolejnym osiągnięciu, jakim jest Turing Natural Language Generation (T-NLG). Jest to nowy, potężny model deep learningowy, o którym Microsoft mówi, że przesunie granice sztucznej inteligencji w dziedzinie przetwarzania języka naturalnego (NLP). W rzeczywistości T-NLG, posiadający 17 miliardów parametrów, jest największym modelem językowym, jaki kiedykolwiek wydano.
Turing-NLG został zaprojektowany jako model generatywny, tzn. taki, który generuje język przydatny w rzeczywistych aplikacjach, takich jak agenty konwersacyjne, systemy pytań i odpowiedzi czy generatory podsumowań dokumentów. W przypadku takich modeli więcej oznacza lepiej:
Zauważyliśmy, że im większy model i im bardziej różnorodne i kompleksowe dane wstępnego treningu, tym lepiej radzi on sobie z generalizacją wielu zadań niższego rzędu nawet przy mniejszej liczbie przykładów szkoleniowych. Dlatego uważamy, że bardziej efektywne jest szkolenie dużego, scentralizowanego, wielozadaniowego modelu i przydzielanie jego możliwości wielu zadaniom aniżeli szkolenie nowego modelu indywidualnie do każdego zadania.
— Corby Rosset, Applied Scientist, Microsoft Research
Aby dowieść skuteczności tego modelu, Microsoft zestawił go z dotychczasowym liderem, MegatronLM autorstwa Nvidii, który używa 8,3 miliarda parametrów. Według wyników opublikowanych na blogu T-NLG osiągnął lepsze wyniki niż MegatronLM w kilku testach, w tym WikiText-103, LABADA oraz w szkoleniach bezpośrednich. Microsoft przeszkolił T-NLG na systemach Nvidia DGX-2 wyposażonych w GPU V100 i połączenia InfiniBand. Zdaniem autorów projektu modele przekraczające 1,3 miliarda parametrów nie mogą "zmieścić się" w pojedynczym GPU, nawet takim z 32 GB pamięci. Model musi być zatem podzielony na równoległe części działające na wielu GPU.
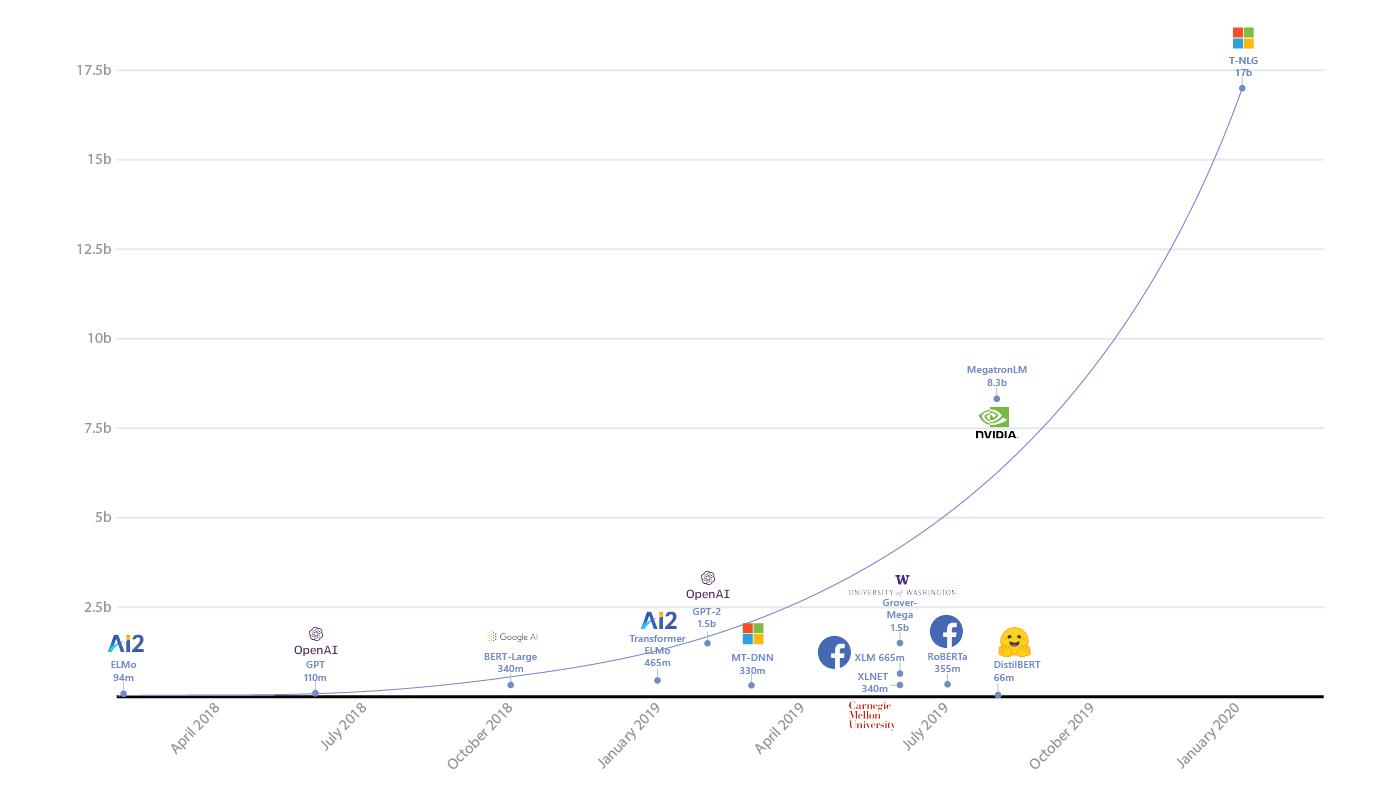
Turing-NLG zdołał prześcignąć swoich rywali w szeregu benchmarków i zdaniem autorów sprawuje się świetnie również w zastosowaniach praktycznych. Jednocześnie nie byłoby to możliwe bez przełomowych produktów biblioteki DeepSpeed (kompatybilnej z PyTorch) i optymalizatora ZeRo. T-NLG został wydany w prywatnej wersji demonstracyjnej, która umożliwia wolne generowanie (freeform generation), odpowiadanie na pytania i tworzenie podsumowań. Na chwilę obecną jest dostępny dla niewielkiego grona użytkowników ze społeczności akademickiej, która prowadzi jego testy i dostarcza Microsoftowi feedbacku. Model jest częścią szerszej inicjatywy o nazwie Project Turing. Ma ona na celu wspomóc ewolucję produktów Microsoftu deep learningiem przy przetwarzaniu zarówno tekstu, jak i obrazów. Osiągnięcia tego projektu są aktywnie integrowane z produktami Bing, Office i Xbox.
Co ciekawe, wspomniane podejście (rozwijanie dużego, scentralizowanego, wielozadaniowego modelu zamiast wielu partykularnych, jednozadaniowych) ma wiele wspólnego z koncepcją sztucznej inteligencji ogólnej (general intelligence AI). Nad jej realizacją pracuje w Microsoft ponad 8000 naukowców. Taka wszechstronna SI byłaby zwieńczeniem kilkudziesięciu lat wysiłków i prawdziwym przełomem.
