
Machine Reading Comprehension (MRC) to specyficzna umiejętność sztucznej inteligencji do przyswajania wiedzy osadzonej w różnego typu źródłach. Innymi słowy jest to zdolność do wyciągania informacji, przydatna czy wręcz niezbędna w wielu realnych scenariuszach. Przykład? Gdy zadamy sztucznej inteligencji pytanie, zwróci ona odpowiedź w języku naturalnym zamiast adresu strony, na której taka odpowiedź może się znajdować.
W przyszłości MCR będzie pomagać lekarzom w przeszukiwaniu tysięcy dokumentów, co znacznie przyspieszy pracę służby zdrowia i rozwinie jej wydajność. Dlaczego mowa dopiero o przyszłości? Dziś większość systemów machine readingowych opiera się zwykle na nadzorowanych przez człowieka danych treningowych, a to oznacza, że rozumieją one tylko te artykuły, które do nich *włożono*, i wymagają manualnego tworzenia zestawów pytanie-odpowiedź. Nietrudno zauważyć, że takie podejście dalekie jest od skalowalności, a ponadto każda dziedzina wiedzy wymaga sporządzania indywidualnych tagów. Przykładowo, jeśli chcielibyśmy w taki sposób stworzyć system dla lekarzy, należałoby przyporządkować oddzielny MCR dla każdej choroby, a każdy z nich musiałby być uzupełniany o aktualną wiedzę z książek i artykułów naukowych.
I tu zaczyna się SkyNet SynNet, nowa "dwustopniowa sieć syntezująca" trenująca MRC. SynNet najpierw uczy się kluczowych zagadnień obszaru wiedzy i koncepcji semantycznych z udostępnionych mu danych. W dalszej kolejności uczy się stawiania pytań w języku naturalnym i tworzenia potencjalnych odpowiedzi w kontekście danego artykułu. Przykład możecie zobaczyć poniżej.

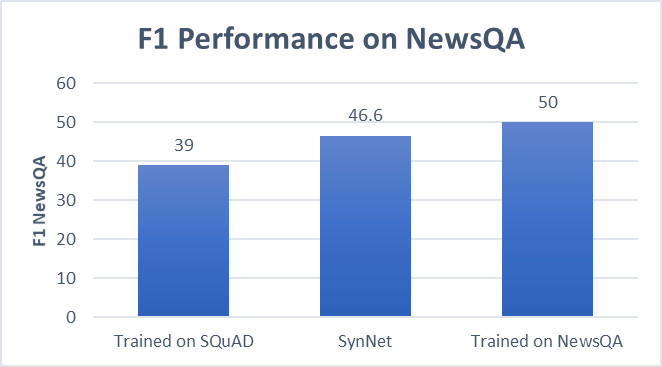
Ciekawym aspektem modelu jest jednak to, że raz wytrenowany może zostać używany w nowych domenach, by generować pseudopytania i odpowiedzi dla danego artykułu. Rezultatem takiego podejścia jest możliwość tworzenia przez SynNet nadzorowanych danych treningowych potrzebnych do wytrenowania konkretnych MRC. To z kolei niweluje konieczność manualnego oznaczania pytań przez człowieka i czyni z SynNet coś w rodzaju nauczyciela dla innych AI. Przykładowo, SkyNet wytrenowany pod kątem artykułów Wikipedii (SQuAD) radzi sobie niemal tak samo dobrze z artykułami/newsami (NewsQA), jak w pełni wytrenowany dla nich system.
Nawet jeśli SynNet znajduje się jeszcze w powijakach, jego możliwości machine readingowe są już pewnym wyznacznikiem kierunku, w którym powinna podążać sztuczna inteligencja. Oczywiście nie wszyscy z takiego kierunku są zadowoleni. Elon Musk przestrzegał już amerykański rząd, by wystosował regulacje względem AI "zanim będzie za późno". Microsoft przekonuje jednak, że jego "zadaniem jest, by te dystopijne scenariusze nie stały się rzeczywistością". Innymi słowy AI musi służyć wspólnemu dobru - pytanie tylko, kto (lub co) będzie ustalać jego definicję.
