
Z początkiem 2023 roku znów mocno iskrzy w tematach AI i text-to-speech. Microsoft Research ogłosił nowy model zamiany tekstu na mowę o nazwie VALL-E, który potrafi naśladować głos dowolnej osoby i wystarczy mu do tego 3-sekundowa próbka mowy. Gdy sztuczna inteligencja nauczy się głosu, może wymawiać nim dowolne treści z zachowaniem jego tonu emocjonalnego.
VALL-E może być używany w wysokiej jakości aplikacjach z zamianą tekstu na mowę, w których dowolna osoba (tak naprawdę zwirtualizowany głos) może wypowiadać dowolne treści. Microsoft nazywa VALL-E "modelem językowym kodeka neuronowego" ("neural codec language model"), który opiera się na technologii zwanej EnCodec. Różni się on od innych metod text-to-speech m.in. tym, że zamiast syntezować mowę poprzez manipulację przebiegami fali, generuje on dyskretny kodek audio z tekstu i wskaźników akustycznych. Wykorzystuje następnie EnCodec do rozbicia tych informacji na dyskretne składniki zwane tokenami i dopasowuje dane treningowe oraz to, co "wie" o głosie osoby, aby określić, jak może on brzmieć z wypowiadanymi frazami.
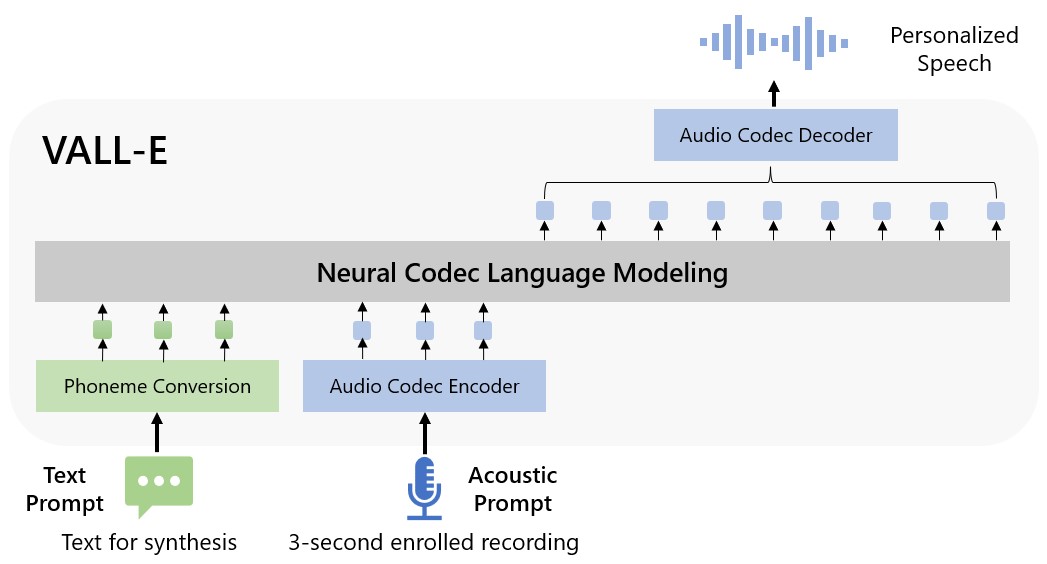
Microsoft wytrenował możliwości syntezy mowy VALL-E w oparciu o bibliotekę dźwiękową LibriLight autorstwa Meta. Zawiera ona 60 tys. godzin nagrań mowy w języku angielskim autorstwa 7 tys. osób, głównie zaczerpniętych z audiobooków LibriVox w domenie publicznej. Aby wygenerować zadowalające efekty, głos w 3-sekundowym samplu musi dokładnie odpowiadać głosowi w danych treningowych.
Bardziej szczegółowe omówienie modelu oraz przykłady dźwiękowe Microsoft udostępnia na stronie VALL-E.
