
Klucze są podstawową koncepcją w teorii relacyjnych baz danych. Zapewniają tabelom możliwość skorelowania ze sobą dwóch lub więcej tabel. Nawigacja w relacyjnej bazie danych zależy od możliwości identyfikacji określonego wiersza w tabeli za pomocą klucza głównego. Artykuł ten poświęcony będzie poświęcony teorii kluczy głównych i obcych oraz zasadom ich działania.
Związek pomiędzy dwoma lub większą ilością tabel to asocjacja (w potocznym bazodanowym języku znana również jako relacja). Asocjacja jest wyrażona za pomocą wartości klucza głównego i kluczy obcych.
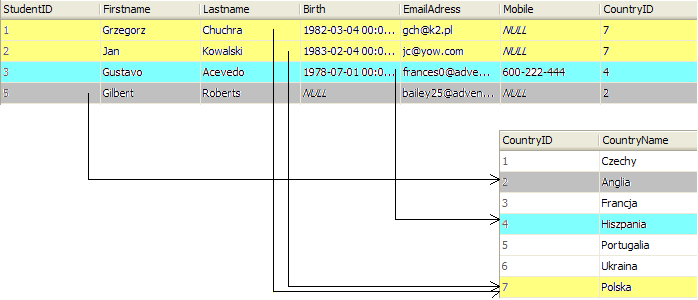
Klucz główny - Primary Key, to kolumna lub zbiór kolumn, które w sposób unikalny definiują wiersz w danej tabeli. Klucz obcy jest kolumną lub zbiorem kolumn, który jest kluczem głównym w innej tabeli. Można powiedzieć, że klucz obcy jest kopią klucza głównego z innej tabeli. Asocjacja jest utworzona pomiędzy tabelami poprzez zaznaczenie, iż wartość z jednej tabeli, w której jest kluczem obcym, jest powiązana z wartością z innej tabeli, gdzie jest kluczem głównym. Ważne jest to, iż wartość klucza obcego nie może istnieć bez powiązania z kluczem głównym. Jeśli w tabeli pracowników mamy pole, które jest kluczem głównym w tabeli z państwami, to nie możemy wpisać w nie wartości, która nie istnieje w tabeli państw. Silnik bazy danych nie zezwoli, aby wstawić wartość klucza obcego, który nie posiada odnośnika na klucz obcy.
Teraz, kiedy mamy na czym skupić naszą uwagę, możemy przejść do opisywania krok po kroku poszczególnych struktur i technik pracy z kluczami. Powiemy, co określa klucz główny, co za tym idzie - w jaki sposób odnaleźć pole, które aplikuje do bycia kluczem. Aby utworzyć taki podstawowy model danych możemy posłużyć się następującym algorytmem:
- identyfikacja pól, które mogłyby się stać kluczami głównymi
- sprawdzenie poprawności kluczy i związków pomiędzy tabelami
- przeniesienie kluczy głównych do innych tabel jako klucze obce.
Określenie kluczy głównych
Klucz główny musi unikalnie identyfikować wiersz. Każdy wiersz w naszej tabeli musi mieć wartość która unikalnie go identyfikuje.
Aby zakwalifikować dany atrybut jako klucz główny, musimy sprawdzić, czy posiada następujące własności:
- musi posiadać wartość dla każdego z wierszy
- dla każdego z tych wierszy wartość musi być unikalna
- wartość ta nie może się zmienić, ani nie może zostać usunięta podczas całego funkcjonowania wiersza w tabeli
Jeśli mielibyśmy tabelę z użytkownikami zarejestrowanymi w
portalu internetowym, kluczem głównym mógłby być login. Jest unikalny w ramach
całej tabeli, a po usunięciu logina użytkownik ulega usunięciu. Kluczem głównym
nie mogłoby być nazwisko, gdyż może być wiele osób, które nazywają się
Kowalski. A to łamie drugą zasadę, która mówi, iż wartość musi być unikalna.
W niektórych przypadkach możemy mieć kilku kandydatów do klucza głównego.
Rozważmy ponownie ten sam przypadek. Przypuśćmy, że mamy dodatkowe informacje o
użytkowniku: datę urodzenia, PESEL, email. Wiemy, że unikalne są dwie wartości:
PESEL i email. Zatem zarówno jedną i drugą możemy zaproponować na klucz główny
w tabeli User. Teraz od nas tylko zależy czy wybierzemy email czy
PESEL. Ja osobiście wybrałbym PESEL ponieważ wyszukiwanie w bazach po wartości
typu INT (czyli typu całkowitoliczbowego) jest znacznie szybsze, niż po
łańcuchu znaków. Jeśli jednak byłby to portal możliwością logowania, trzeba
wziąć pod uwagę, że zmuszenie użytkownika, aby przy logowaniu wpisywał PESEL jest
trudniejsze niż skłonienie go do wpasania adresu email.
Klucze złożone
Czasem pojedyncza wartość nie wystarczy na jednoznaczne określenie wiersza.
Jeśli chcielibyśmy zapisać oceny z przedmiotów dla danego studenta musielibyśmy zapisać następujące informacje: przedmiot, z którego ocena została wystawiona, studenta któremu ją wystawiamy i samą ocenę. W tym celu należało by stworzyć następującą tabelę.
|
LessonID |
StudentID |
Mark |
|
01 |
01 |
5 |
|
01 |
02 |
2 |
|
02 |
01 |
3 |
Przyporządkowujemy zajęciom o kluczu głównym 01 i studentowi o kluczu głównym 01 ocenę pięć. Zaś temu samemu studentowi tylko dla innego przedmiotu o kluczu głównym 02 już ocenę trzy. W tym wypadku mamy złożony klucz główny. Ponieważ ani LessonID ani też StudentID pojedynczo nie spełnia wymagań unikalności klucza głównego, musimy zastosować klucz złożony. W tym wypadku kluczem będzie powiązanie LessonID i StudentID. Pojedynczo żaden z nich nie może spełnić tego zadania, ale w sumie unikalnie określają każdy wiersz.
Sprawdzenie poprawności kluczy
Podstawowe zasady zarządzania i identyfikacji kluczy głównych:
- każda tabela w bazie danych powinna posiadać klucz główny unikalnie identyfikujący wiersz.
- klucz główny nie może być opcjonalny. Czyli nie może posiadać wartości nieokreślonej.
- klucz główny nie może się powtarzać. Może być co najwyżej jedna wartość atrybutu klucza głównego w danej tabeli.
Sprawdzenie poprawności kluczy
Klucze obce są polami, które umożliwiają zachowanie związku pomiędzy identyfikatorem w tabeli, a tabelą, z której wartość ta się wywodzi. Klucze obce umożliwiają zarządzanie integralnością i spójnością danych. Każda asocjacja w bazie powinna być opatrzona kluczem obcym.
W przykładzie ze złożonym kluczem głównym mieliśmy do czynienia z dwoma
kolumnami LessonID oraz StudentID. Jeśli
zobaczylibyśmy, jak to wygląda w szerszym kontekście, moglibyśmy wyciągnąć
bardzo ciekawy wniosek. LessonID i StudentID są
kluczami obcymi z tabel Lesson i Student. Ponieważ
za pomocą LessonID możemy pobrać informacje o tym, jakiej lekcji
dotyczy LessonID 01, zaś z tabeli Student możemy
wybrać informacje o osobie, do której StudentID jest
przyporządkowane.
To jest właśnie istota kluczy. Nie musimy przechowywać wartości pola, wystarczy
nam sam klucz. Za pomocą jego unikalnej wartości możemy bez problemu wyciągnąć
interesującą nas wartość.
Podsumowanie
Klucze główne i klucze obce są podstawą teorii relacyjnych baz danych. Każda z tabel powinna mieć kolumnę lub kolumny, na które można nałożyć klucz główny jednoznacznie określający każdy z wierszy. Każda tabela wykorzystująca w jakiś sposób dane z innych tabel powinna być powiązana z nią za pomocą klucza obcego
